Teach
About
Privacy & Legal
Code.org partners with researchers for a variety of types of studies. Researchers also conduct conduct their own work using data provided by Code.org (see below) or just on their own using Code.org materials.
Estimating the Causal Effect of Code.org Teacher Training Program on Advanced Placement Outcomes
Hour of Code impact study 2016 (PDF)
Other reports
Numerous academic organizations have asked to access anonymized course-progress data from our Code Studio tutorials in order to research the student learning process and ideas for improving on it.
As explained in our privacy policy, when students solve coding puzzles on our platform, we save the number of tries a student takes to solve a puzzle, including the code they submit. This is how we generate progress reports for students and teachers. This same data can also help identify how to improve our tutorials.
We're interested in exploring ways to share just the machine-level data (with no student identifying information) to allow 3rd party researchers to help us improve our service, without any risk of impact on student privacy.
We'd love to do a lot more in this space, and we're limited by our own staff's ability to support third parties. We recently hired a data engineer to help us perform our own analysis and also to support academic efforts using the same data. We're hoping to open up more data soon.
In the meantime, we've done one experiment with researchers at Stanford University as explained below.
We'd like to take this further and look at what factors influence learning. For example, how do different puzzle types promote learning? How well do students transfer learning from one type of puzzle to another? How can we give students the right type of hints at the right time? What can we do to help students persist through hard problems instead of giving up? How do external factors (gender, age, class size, geography, etc.) impact student learning and what can we do to support diverse classes?
If you're interested in working with us on these questions (and more), email research@code.org.
Our first foray in this space has been a partnership with a Stanford University research team led by Mehran Sahami. Stanford researcher Chris Piech evaluated the various computer programs that students submitted to two computer programming puzzles from our popular Hour of Code tutorial. The dataset below was generated for the paper Autonomously Generating Hints by Inferring Problem Solving Policies by Piech, C. Mehran S. Huang J and Guibas L.

The link below is a dataset of anonymized, aggregated data of student attempts to solve these two puzzles, as explained in the readme.txt file and below. Please contact piech@cs.stanford.edu if you have questions.
The dataset is FERPA compliant. It does not contain any identifiable information such as database IDs, timestamps, gender, age, or location data. Absolutely no information is included in the dataset which could be used to identify a student. For more information on how we protect private information, see our terms of service and privacy policy.
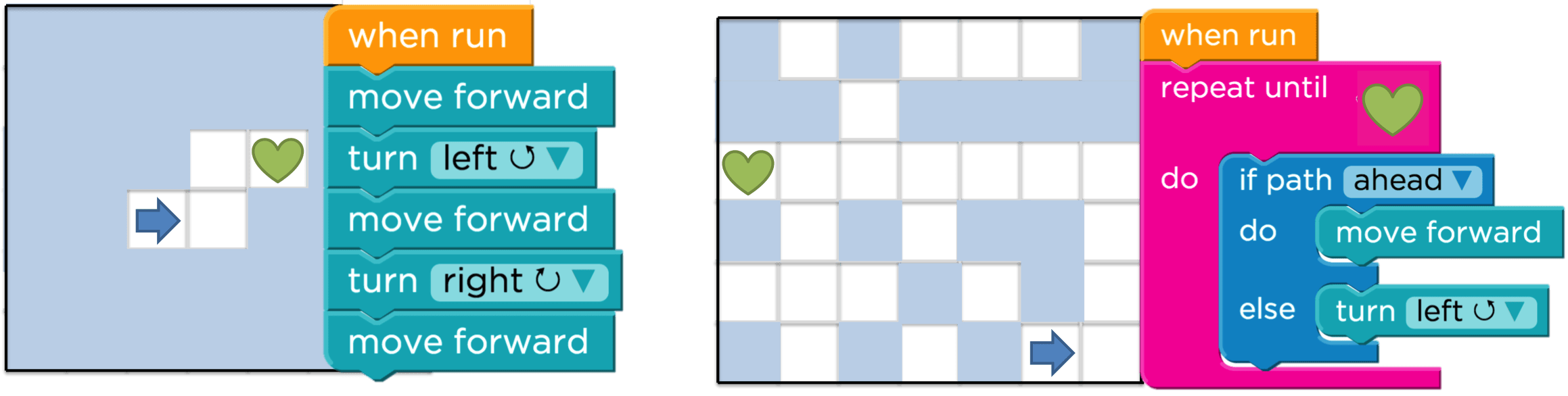
This is a dataset of aggregate user interaction data for logged-in users working on two computer programming challenges, Hoc4 and Hoc18 from December 2013 to March 2014. The solution to Hoc4 requires students to string together a series of moves and turns. The solution to Hoc18 requires an if/else condition inside a for loop. Submissions are collected each time a logged in user executed their code.
Schematic of the maze and example solution for Hoc4 (left) and Hoc18 (right). The arrow is the agent and the heart is the goal.
| Statistic | Hoc4 | Hoc18 |
|---|---|---|
| Unique Students | 509,405 | 263,569 |
| Code Submissions | 1,138,506 | 1,263,360 |
| Unique Submissions | 10,293 | 79,553 |
| Pass Rate | 97.8% | 81.0% |
The Abstract Syntax Trees of all the unique programs. Each file is an AST in json format where each node has a "block type", a nodeId and a list of children. The name of the file is the corresponding astId. AstIds are ordered by popularity: 0.json is the most common submission, followed by 1.json etc. The file asts/counts.txt has corresponding submission counts and asts/unitTestResults.txt has the code.org unit test scores.
Graphs/roadMap.txt stores the edges of the legal move transitions between astIds as allowed by the code.org interface.
A dataset gathered by Piech et Al to capture teacher knowledge of "if a student had just submitted astId X, which adjacent astId Y would I suggest they work towards."
Each file represents a series of asts (denoted using their astIds) that one or more students went through when solving the challenge. File names are the trajectoryIds. The file trajectories/counts.txt contains the number of students who generated each unique trajectory. The file trajectories/idMap.txt maps "secret" (eg anonymized) studentIds to their corresponding trajectories.
We interpolate student trajectories over the roadMap graph, so that for each student we attempt to calculate the Maximum A Posteriori path of single block changes that each student went through. The file interpolated/idMap.txt contains the mapping between interpolated trajectory Ids and trajectory Ids.
The students who attempted and completed the subsequent challenges (Hoc5 and Hoc19 respectively). The file nextProblem/attemptSet.txt is the list of "secret" (eg anonymized) studentIds of users who tried the next problem. The file nextProblem/perfectSet.txt is the list of "secret" (eg anonymized) studentIds of users who successfully completed the next problem.
Some ASTs do not compile in the interface and are thus not captured. This dir contains a list ASTs that do not compile but are still relevant for understanding user transitions.
